在对 K8S 控制节点有 HA 方面需求的话,应考虑 https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/ha-topology/ 提到的两种拓扑。
HA 的方式除了让 controll nodes 和 etcd 有多个节点外,另外一个就是对外需要 VIP + LoadBalance 的功能。https://github.com/kubernetes/kubeadm/blob/master/docs/ha-considerations.md#options-for-software-load-balancing 讲述了如果使用 keepalived 和 haproxy 来实现这个前提。这个连接讲述了三个部署 keepalive, haproxy 的方式。推荐还是使用第二或第三种,第一种方式仅作为我们理解背后工作的逻辑就好。
因为这里只是开发环境使用的 k8s,所以就不以 HA 的方式安装 k8s 了。。无非就是多了两个步骤:
1)准备 VIP/LB;
2)kubeadm –init 时,用–control-plane flag 添加其它 CP 节点而已)。
1)为 kubeadm 准备虚拟机和 docker
准备开发用 KVM HOST 并 创建网桥
步骤参考:
a) 准备 kvm:https://dhyuan.github.io/2020/09/19/devops/create_gust_hosts_on_kvm_by_ansible/
b) 创建网桥:https://dhyuan.github.io/2020/09/21/devops/create_bridge_on_centos7/
下载创建虚拟机的 CentOS7 镜像
curl -O https://cloud.centos.org/centos/7/images/CentOS-7-x86_64-GenericCloud.qcow2
sudo mv -iv CentOS-7-x86_64-GenericCloud.qcow2 /var/lib/libvirt/images/
得到一键安装 GuestHost 和 Docker 的 ansible 脚本。
注意这里是使用分支 devenv 上的代码。
cd ~/devenv_bootstrap
git clone -b devenv https://github.com/dhyuan/virt-infra-ansible.git
cd ~/devenv_bootstrap/virt-infra-ansible/roles
git clone -b devenv https://github.com/dhyuan/ansible-role-virt-infra
ansible-galaxy install \
--roles-path ~/.ansible/roles/ \
git+https://github.com/haxorof/ansible-role-docker-ce.git,2.7.0
根据自己的需求修改 K8S master、nodes 节点的主机配置。
注意:节点名称已经改为使用-而不是_以符合 DNS 规范。这点是 K8S 的要求,但是和 yaml 的格式规范使用下划线有点而冲突。
cd ~/devenv_bootstrap
vi inventory/k8s-masters.yml
vi inventory/k8s-nodes.yml
一键创建 master + nodes 虚拟机
ansible-playbook ./virt-infra.yml \
--limit kvmhost,k8s-masters,k8s-nodes
一键在 master、nodes 节点上安装 docker
ansible-playbook ./install_docker.yml \
--limit k8s-masters,k8s-nodes -v \
-e '{"docker_repository_url": {"CentOS": "http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo"}}'
验证环境
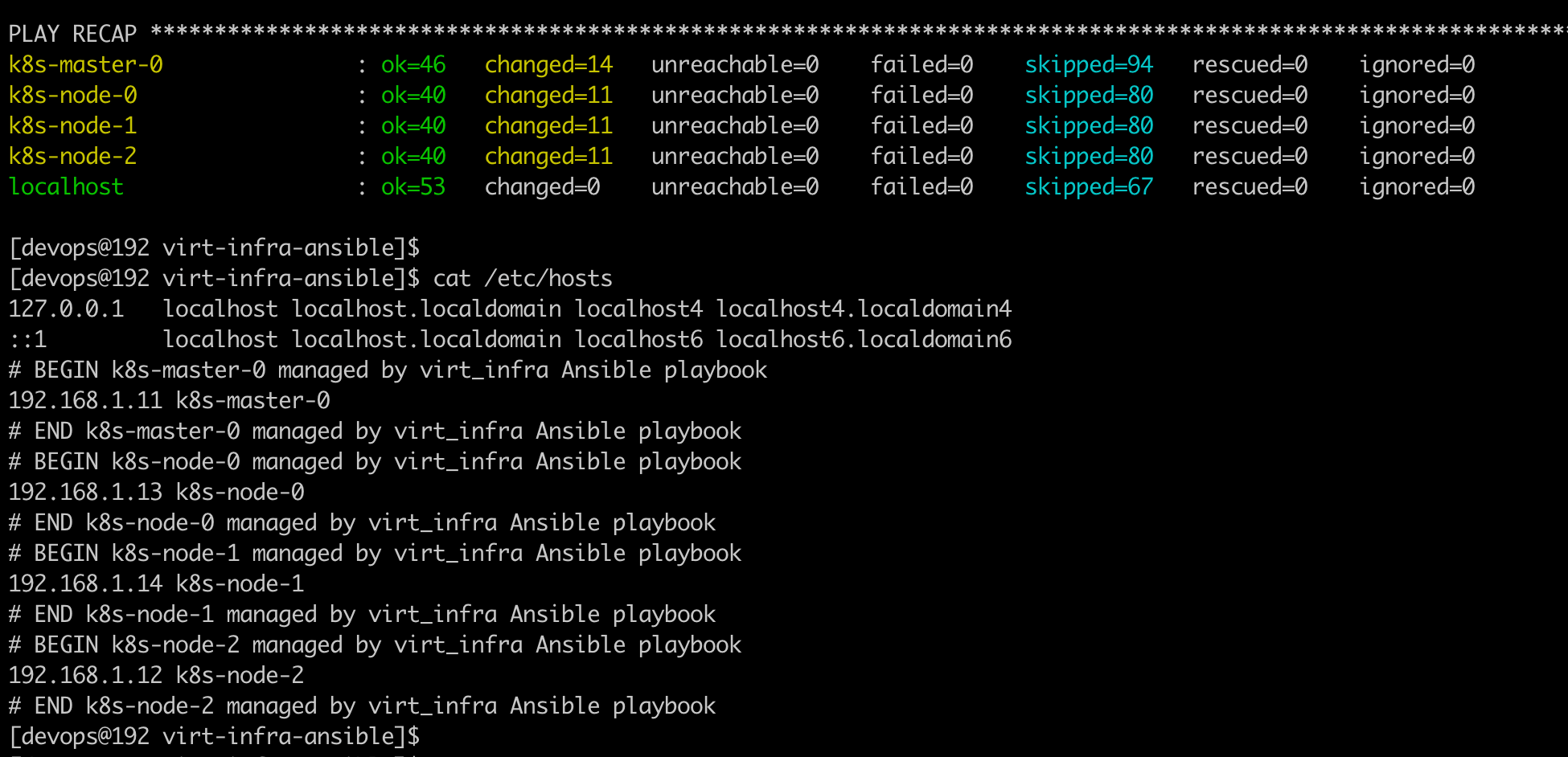
在 KVM HOST 查看/etc/hosts 里面记录了各个主机节点 IP。
各节点互相 ping
登录到各主机检查 docker 引擎是否工作正常。
2)安装 kubeadm,此步骤需要在各个 master、nodes 节点执行。
下面基本参照官网 https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/ 以及另阿良的
https://mp.weixin.qq.com/s/8JznAEKe6b-wE-kNx7_Svg 来进行。
设置 kubernets yum 源
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
# 使用阿里源
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
enabled=1
gpgcheck=0
repo_gpgcheck=0
exclude=kubelet kubeadm kubectl
EOF
确保将桥接的 IPv4 流量传递到 iptables 的链:
加载 br_netfilter 模块加载:
sudo modprobe br_netfilter
lsmod | grep br_netfilter
设置 br_netfilter,也可设置在/etc/sysctl.d/99-sysctl.conf 文件里。
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-iptables=1
EOF
sudo sysctl --system
设置禁用 SELinux
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
让各机器时间同步
因为这里的环境是运行在 KVM 里的虚拟机,所以这一步可忽略。在生成环境中,各机器时间应该同步。
yum install ntpdate -y
ntpdate time.windows.com
安装 kubeadm
sudo yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
yum list installed | grep kube
此时可用的最新版本是 1.19.2。
enable kubelet
sudo systemctl enable kubelet
sudo systemctl status kubelet
此时 kubelet 的状态是 failed,因为 api server 还没有起来。
3)构建集群
在规划的 master 节点上首先初始化一个集群的 master 节点
这里要注意因为 gcr.io 被墙, 所以是使用 ali 镜像。各参数含义参考:https://kubernetes.io/zh/docs/reference/setup-tools/kubeadm/kubeadm-init/
另外,关于 pod-network-cidr 的意义这篇文章非常好:https://blog.csdn.net/shida_csdn/article/details/104334372
执行 kubeadm 时需要下载镜像,所以需要稍等一会儿。
sudo kubeadm init \
--apiserver-advertise-address=192.168.1.11 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.19.2 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16
kubeadm init 命令输出大致如下,并且 kubelet 服务也已经正常。
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.11:6443 --token 67y1i4.686gqk1w73isp3op \
--discovery-token-ca-cert-hash sha256:ccecf99d92615da1c67878029d79ae7323daac45476168091281ac80ddf0571d
[devops@k8s-master-0 ~]$
执行以下命令,让普通用户也能执行 kubectl 命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
安装网络插件 flannel
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 替换 quay.io 为国内镜像 quay.mirrors.ustc.edu.cn
kubectl apply -f kube-flannel.yml
# 验证网络插件安装成功
kubectl get pods -n kube-system
如果需要,可以删除刚才安装的 flannel 插件:
kubectl delete -f kube-flannel.yml
ip link
ip link delete cni0
ip link delete flannel.1
把 nodes 加入集群
在各个 node 节点运行以下命令:
sudo kubeadm join 192.168.1.11:6443 --token 67y1i4.686gqk1w73isp3op \
--discovery-token-ca-cert-hash sha256:ccecf99d92615da1c67878029d79ae7323daac45476168091281ac80ddf0571d
在 master 节点,验证 nodes 都成功加入 K8S 集群:
[devops@k8s-master-0 ~]$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master-0 Ready master 72m v1.19.2
k8s-node-0 Ready <none> 4m41s v1.19.2
k8s-node-1 Ready <none> 76s v1.19.2
k8s-node-2 Ready <none> 89s v1.19.2
[devops@k8s-master-0 ~]$
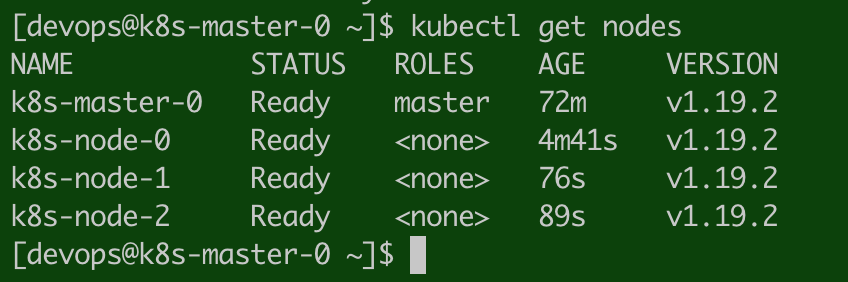
至此,已经完成了 Kubernetes 集群的搭建。
Reference:
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm
https://mp.weixin.qq.com/s/8JznAEKe6b-wE-kNx7_Svg
https://my.oschina.net/u/3021599/blog/4308021
https://cloud.tencent.com/developer/article/1525487
https://galaxy.ansible.com/geerlingguy/docker
https://galaxy.ansible.com/
在 CentOS7 上运行个 DHCP Server:https://www.tecmint.com/install-dhcp-server-in-centos-rhel-fedora/
https://www.cnblogs.com/hellxz/p/11044012.html