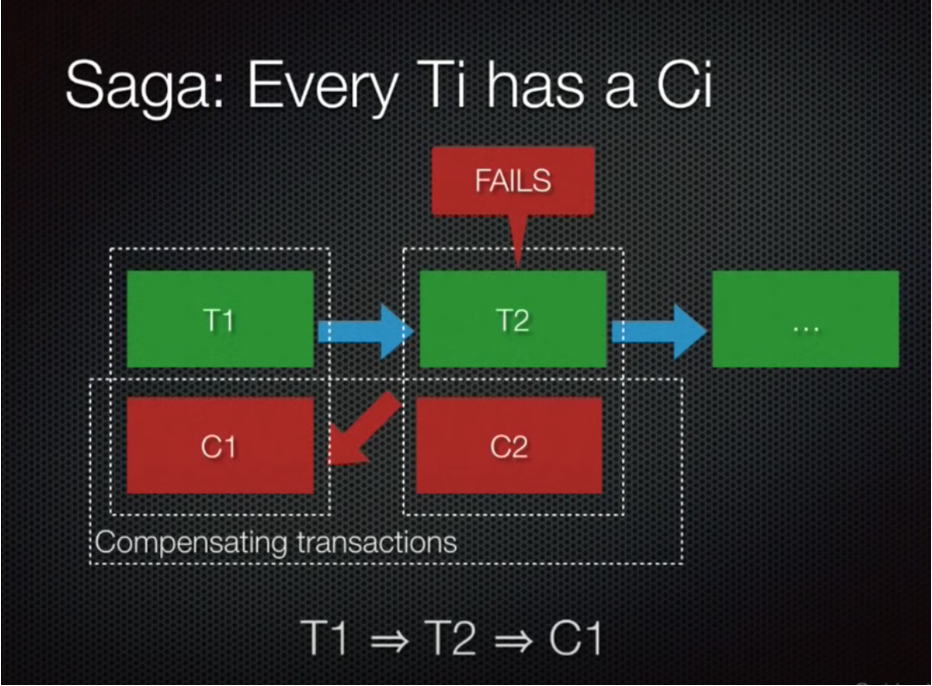
glimpse of saga
项目中遇到多个微服务调用需要考虑和处理某个环节失败时的处理。虽然这里不需要很强的事务概念,但是需要对失败的动作进行重试等操作。这里的重试本质上就是 rollback 的另一种形式,在 saga 里算是“forward recovery”。
借机又翻看了一下相关的文章,贴到了文末。
Saga vs TCC
- Saga 相比 TCC 的缺点是缺少预留动作,所以某些情况补偿的实现比较麻烦甚至无法撤销只能补救。不过没有预留动作也意味着不必担心资源释放的问题。
- TCC 最少通信次数为 2n,Saga 为 n(n=sub-transaction 的数量)。
- 第三方服务没需要提供有 Try 接口。
总体感觉下来 SAGA 更适合微服务的多数场景。
Simple Saga
解决这类问题当然可以直接引入一些已存在的 saga 框架,不过这里存在学习、部署等成本。如果只是小范围的解决问题,或许可以使用下面的形式。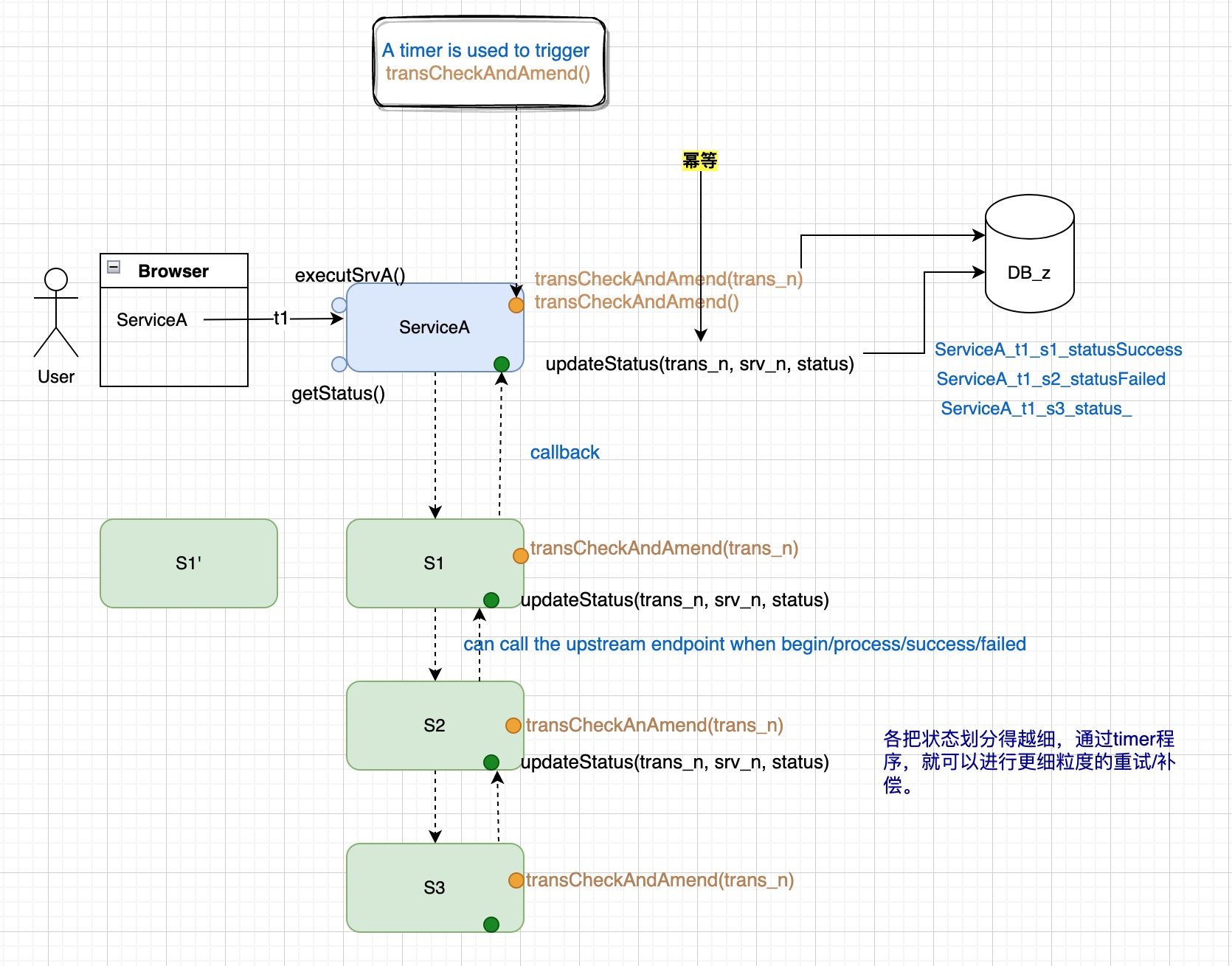
上面示意图针对的场景是:服务的执行都需要较长时间、并且是异步调用。
如果各个服务执行时间都不长,一个调用链下来小于几百毫秒,那么直接使用 reactive style 的编码也应该可以。
因为各服务执行时间较长,所以不能使用同步调用。这里耗时指的是对于有 UI 的程序至少影响到到 UI 前的用户,如果是后台应用那么至少阻塞的时长影响到系统的资源可用性。
即使服务执行时间短,同步调用也会使调用链的 availability 降低,所以微服务的场景下使用异步调用有天然的好处。
从这个示意图其实可以看作是 Chris 演讲中提到的最最原始的模式。可以把 callback 看作是 saga 事务参与方发送消息到 message broker。而调用链的第一个节点就充当了 saga 的协调者。
各个微服务的 updateStatus 端点就是 message 的 listner,只不过这里直接通过 callback 实现而没有利用消息队列。
最开始的 endpoint 负责生成一个 transactionId 并依次传递给每个下游服务,每个下游服务通过 callback 把自己的状态更新给上游。
getStatus() 端点提供给 UI 获取当前状态。

transCheckAndAmend(trans_n) 每个服务暴露的业务方法都需要提供一个补偿方法。
服务的入口方法其实充当了协调者, 更像 orchestration 的,而不是 choreography 的。
Timer 是个后台定时器不停的检查服务状态,如果状态不成功就调用 compensating endpoint.
Reference:
[1]: Saga 的经典论文 https://www.cs.cornell.edu/andru/cs711/2002fa/reading/sagas.pdf
[2]: 《Microservice Pattern》”Chapter4, Managing transactions with sagas”
[3]: Chris Richardson 在 2017 年的演讲:https://www.youtube.com/watch?v=YPbGW3Fnmbc
一些中文网文:
[3] 分布式事务:Saga 模式 https://www.jianshu.com/p/e4b662407c66
[4] 七种分布式事务的解决方案 https://cloud.tencent.com/developer/article/1806989
[5] 分布式事务六种解决方案 https://zhuanlan.zhihu.com/p/183753774